Preliminaries
Reinforcement learning (RL) is a powerful approach to train an actor to deal with complex and dynamic environments. However, RL algorithms require a lot of data to learn effective policies, which can limit their practical applications in real-world scenarios. Gathering data can be time-consuming and expensive. Additionally, data collection can sometimes even be dangerous, especially in environments that involve physical robots or complex simulators. An example for this is the training of self-driving cars on public roads. When autonomous vehicles share the roads with human drivers to collect data, a simple mistake by the agent could lead to a dangerous incident. Therefore, there is a growing demand for RL methods that can learn from as few samples as possible while maintaining high performance. This blog will cover a small project on how training an agent in such scenarios can be done in a safer manner.
The Project
The experiments performed use the LAMBDA agent by Yarden As et al.
Background
LAMBDA
LAMBDA is a Bayesian world model based reinfocement learning (RL) agent, that solves tasks in a given virtual environment. The agent can be benchmarked using a suite of safety gym environments. The environment can be modeled as a constrained Markov decision process (CMDP), which can be navigated using learned policies
Bayesian Optimization
Bayesian optimization (BO) is a sequential optimization technique, which is especially present in areas where we do not have any prior information about the function that is to be optimized
In this seminar project, the expected improvement (EI) acquisition function is used as a sampling policy
The Expected Improvement Acquisition Function
In the hyperparameter optimization context, many sampling policies are based on the concept of maximizing the probability of an arbitrary point $\bold{x}$ of the black box function $f$ improving upon the value $f(\bold{x})$ of the previous best point $\bold{x}^+$.
In the context of Gaussian processes, $f(\bold{x})$ is not a specific function value, but rather a normal distribution over possible function values. The probability of improving upon the previous best observation $f(\bold{x^+})$ is therefore the area under the probability density function centered at the gaussian process mean $\mu$ at point $\bold{x}$, that lies above $f(\bold{x^+})$. From this concept, we can derive our acquisition function.
The expected improvement acquisition function we use in our optimization procedure is defined as follows in
The Gaussian Process
A Gaussian process (GP) is a collection of infinitely many random variables, where all variables of any finite subset have a joint Gaussian distribution
While analytically deriving the mean and variances of a GP is certainly viable for smaller use cases, the performace scales quite poorly. For this reason, oftentimes stochastical approximation methods are used to approximate GPs, similarly to the SWAG algorithm used for LAMBDA BoTorch-library
Implementation
The BO algorithm is implemented in an offline fashion, similarly to the one presented in lambda_ and discount. The library used to implement the Gaussian process and the acquisition function is BoTorch
The Algorithm
Experiment Setup
To demonstrate the optimization process of the LAMBDA-agent, we will optimize the two hyperparameters lambda_ ($\lambda$) and discount ($d$). These parameters can be found in the critic model of the agent and therefore could have a significant impact on the agents performance. The performance metrics used here are the average undiscounted episodic reward return $\hat{J}(\pi)$, the average undiscounted episodic cost return $\hat{J}_c(\pi)$, and the normalized sum of costs during training (or cost regret) $\rho_c(\pi)$, as defined in
First Results
For the first test run, I defined the objective function to optimize as $\hat{J}_c(\pi) + \rho_c(\pi)$. Minimizing this function minimizes the cost return of the agent, during training and testing. The reward is ignored for now. In the following interactive figure you can click through the gaussian process mean after each consecutive sample.
We can see that in this example, the minimum of the objective function is found relatively quickly, only after taking a few samples. Let us now take a look at the performance of the agent trained on the best found hyperparameters. The following plot shows the average reward return, average cost return and the cost regret.
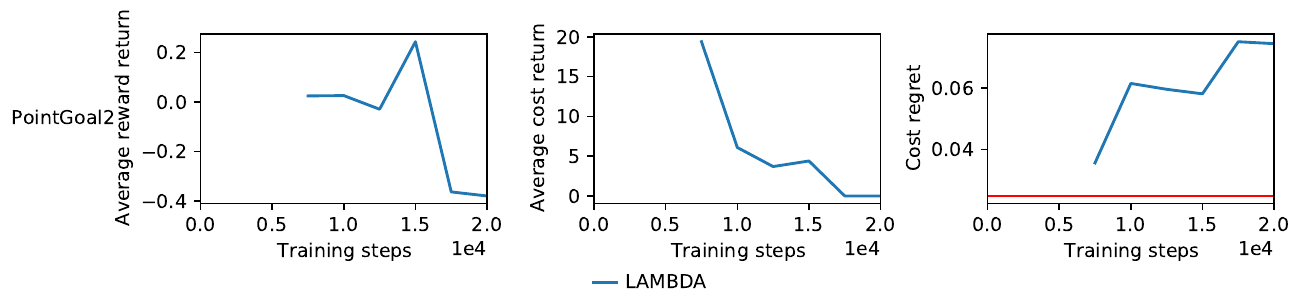
Since we did not include the reward return in the objective function, it is not being optimized. While the average cost return is decreasing with more training steps, as expected, the cost regret is actually rising. The reason why this is happening could be the small magnitude of the measurement when compared to the average cost return. Furthermore, you might notice the smaller number of training steps when compared to the experiments in the paper. We will discuss the reason for this in the last section. For now, we need to improve the objective function.
Second attempt Results
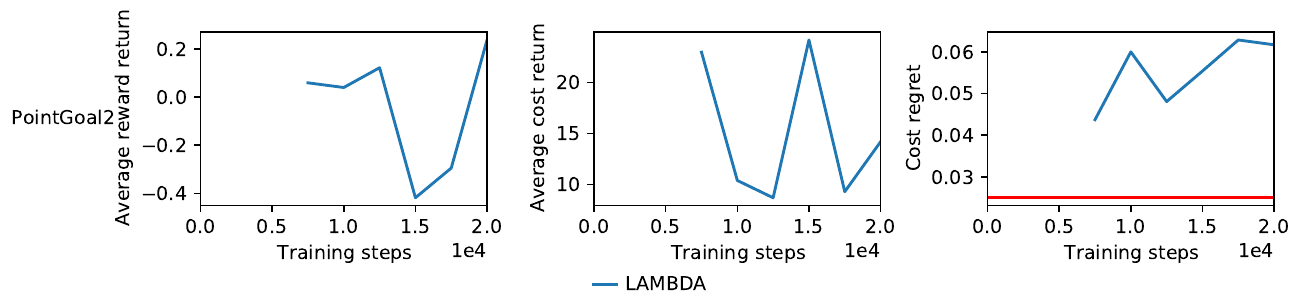
We will now alter the objective function to include the average undiscounted episodic reward return, and futhermore to try to balance out the differences in magnitude by multiplying the cost regret with a constant factor. The latter will hopefully minimize the cost during training. We obtain $\min \hat{J}(\pi) + \hat{J}_c(\pi) + 100 \cdot \rho_c(\pi)$. The optimization process can be seen in the following figure.
We observe two minima found by the optimization procedure. Figure 4 shows the performance metrics of the best agent again. The average reward return is now actually improving, while the cost return seems to decrease. Unfortunately, the cost return is unaffected by the increased objective function weight. We note that, while looking better then the first attempt, there is still not a noticable performance improvement. I attribute this fact to several problems, which we will discuss in the next section.
Problems and Prospect
Training LAMBDA is computationally expensive. However, the present experiments are limited by insufficient resources, resulting in a prolonged optimization process of approximately three days to obtain 20 samples. The number of training steps and epochs is already significantly reduced when compared to the paper, which certainly affects the accuracy and representability of the results obtained. When comparing the results of this experiment to the paper results, it becomes apparent that a lot longer training times are needed for the results to stabilize and potential performance benefits to materialize. For this reason, future experiments should be performed on a more capable system, to verify if the implemented optimization procedure works as intended. This would furthermore enable the exploration of more elaborate objective functions than the one used here.
Furthermore, the current implementation of the BO optimization procedure can be numerically instable in some cases. This shows in some of the GP mean plots as aprupt color gradient changes. A stochastic approximation of the exact GP model could help here.
Lastly, more representative results, achieved through longer training times, could also be compared to results achieved using a gradient descent based optimization algorithm, to demonstrate the increased sampling efficiency.
Unfortunately, due to time constraints, I was not able to further explore these suggestions. Despite some problems and road blocks in this project, I learned a lot about Gaussian processes, Bayesian optimization and reinforcement learning.