viewof angles = Inputs.form({
back1: Inputs.range([-1,1], {value:0, step:0.1, label: "angle back 1:"}),
back2: Inputs.range([-1,1], {value:0, step:0.1, label: "angle back 2:"}),
back3: Inputs.range([-1,1], {value:0, step:0.1, label: "angle back 3:"}),
front1: Inputs.range([-1,1], {value:0, step:0.1, label: "angle front 1:"}),
front2: Inputs.range([-1,1], {value:0, step:0.1, label: "angle front 2:"}),
front3: Inputs.range([-1,1], {value:0, step:0.1, label: "angle front 3:"}),
})
leg_length = 0.4;
foot_length = 0.2;
back1 = angles.back1 + 0.6;
back2 = back1 + angles.back2 - 1.3;
back3 = back2 + angles.back3 + 1.6;
front1 = angles.front1 - 0.4;
front2 = front1 + angles.front2 + 0.8;
front3 = front2 + angles.front3 + 0.3;
joint_back1 = ({x: -0.5, y: 0.4});
joint_back2 = ({x: joint_back1.x + Math.sin(back1) * 0.40, y: joint_back1.y - Math.cos(back1) * 0.40});
joint_back3 = ({x: joint_back2.x + Math.sin(back2) * 0.40, y: joint_back2.y - Math.cos(back2) * 0.36});
joint_back4 = ({x: joint_back3.x + Math.sin(back3) * 0.16, y: joint_back3.y - Math.cos(back3) * 0.18});
joint_front1 = ({x: 0.5, y: 0.4});
joint_front2 = ({x: joint_front1.x + Math.sin(front1) * 0.33, y: joint_front1.y - Math.cos(front1) * 0.3});
joint_front3 = ({x: joint_front2.x + Math.sin(front2) * 0.30, y: joint_front2.y - Math.cos(front2) * 0.28});
joint_front4 = ({x: joint_front3.x + Math.sin(front3) * 0.15, y: joint_front3.y - Math.cos(front3) * 0.16});
line_conf = ({x: 'x', y: 'y', strokeWidth: 15});
line_conf1 = ({...line_conf, stroke: '#91775b'});
line_conf2 = ({...line_conf, stroke: '#956f6e'});
Plot.plot({
marks: [
Plot.line([joint_back1, joint_front1], line_conf1), // back
Plot.line([joint_front1, {x: joint_front1.x+0.2, y: joint_front1.y+0.2}], line_conf1), // head
Plot.line([joint_back1, joint_back2], line_conf1), // back leg 1
Plot.line([joint_back2, joint_back3], line_conf2), // back leg 2
Plot.line([joint_back3, joint_back4], line_conf2), // back foot
Plot.line([joint_front1, joint_front2], line_conf1), // front leg 1
Plot.line([joint_front2, joint_front3], line_conf2), // front leg 2
Plot.line([joint_front3, joint_front4], line_conf2), // front foot
],
width: 600,
height: 400,
x: {
domain: [-1,1],
axis: null,
},
y: {
domain: [-2/3,2/3],
axis: null,
},
});Uncertainty-Based Offline Reinforcement Learning with Diversified Q-Ensemble
Abstract
Overestimation of out-of-distribution actions is a key problem in offline reinforcement learning which can pose serious safety risks. In this blog we explore two state-of-the-art algorithms proposed by An et al. (2021), SAC-N and EDAC. They handle uncertainty by training multiple critics in a Soft Actor Critic approach and taking the most pessimistic q-value guess to avoid overestimation.
Introduction
Why Offline-RL?
Training of RL algorithms require active interaction with the environment. Training can become quite time-consuming and expensive. It can even be dangerous in safety-critical domains like driving or healthcare. A trial-and-error procedure is basically prohibited. We cannot as an example let an agent explore, make mistakes, and learn while treating patients in a hospital. That’s what makes learning from pre-collected experience so relevant. And fortunately we have already in many domains existing large datasets. Offline-RL therefore aims to learn policies using only these pre-collected data without further interactions with the environment.
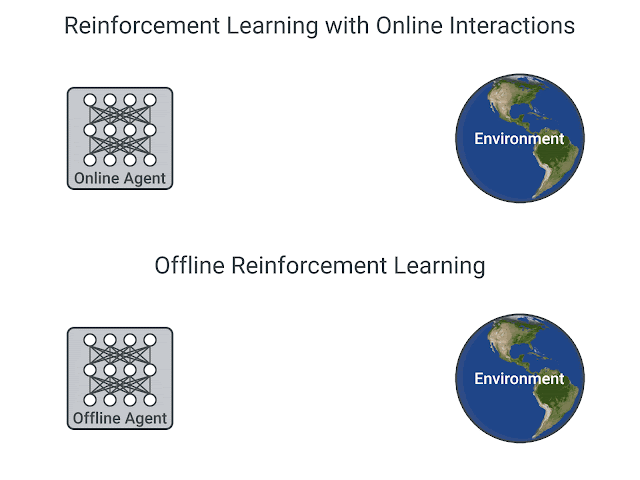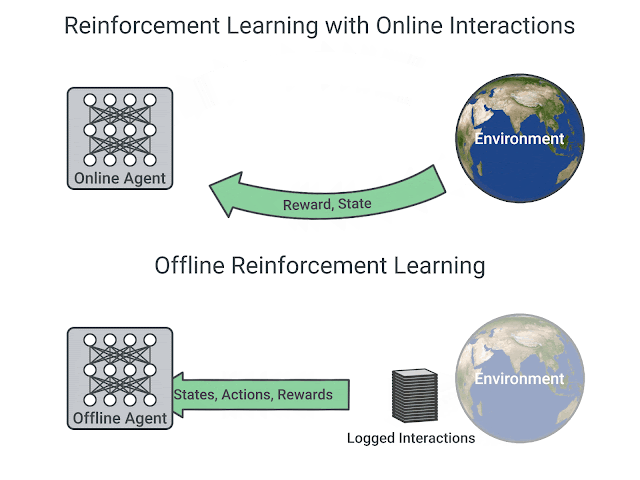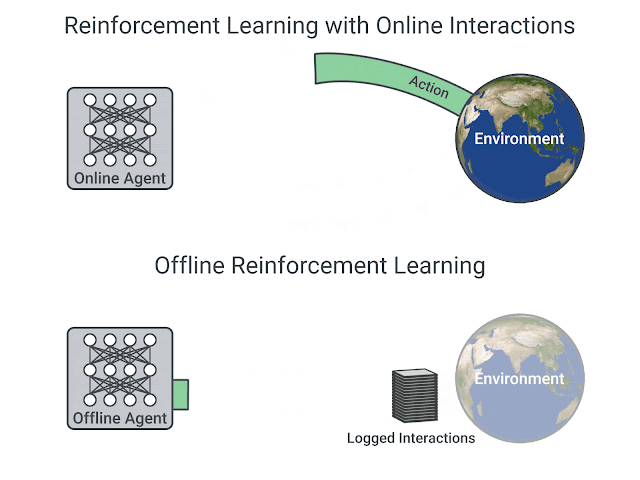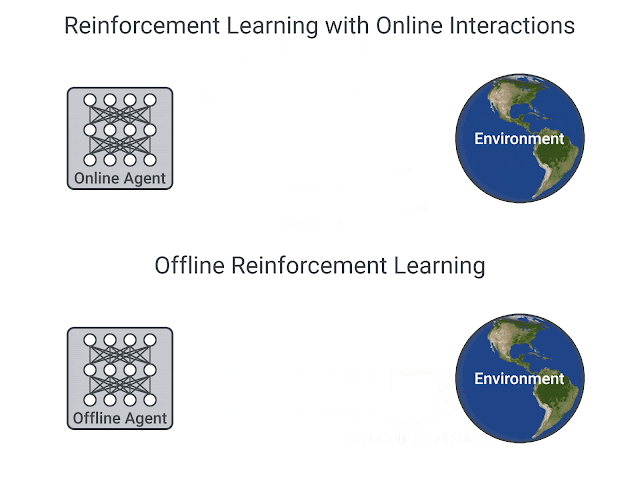
What properties make offline-RL difficult?
But offline RL comes with its own challenges. By far the biggest problem are so called out of distribution (OOD) actions. OOD actions refer to actions taken by an agent that fall outside the range of actions observed in the training dataset. State-action space can become so vast that the dataset cannot cover all of it. Especially narrow and biased datasets lack significant coverage and can lead to problems with OOD actions. For example, healthcare datasets are often biased towards serious cases. Only seriously ill people are getting treated, while healthier people are sent home untreated.
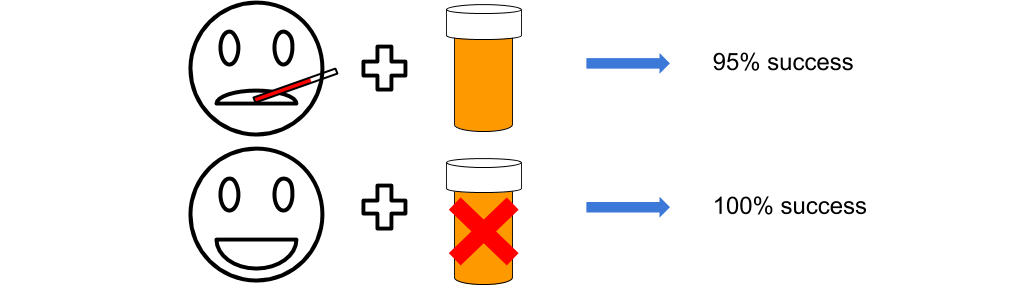
A naive algorithm might now conclude that treatment causes death, since there were no fatalities in the untreated (= healthy) patients. Choosing to not treat a severely sick patient is something that never happened in the data, since the doctor would thereby violate his duty of care. Not treating a sick patient is therefore an OOD action. Vanilla RL algorithm might heavily overestimate the Q-values of OOD state-action pairs.
How to deal with OOD state-actions?
“Avoid OOD state-actions!”, has been the approach of many offline RL algorithms. This can be achieved by regularizing the policy to be close to the behavior policy that was used to collect the data. A more recent approach is to penalize the Q-values to be more pessimistic as done in Conservative Q-learning for Offline RL (CQL). But if we use this approach we require either (a) an estimation of the behavior policy or (b) explicit sampling from OOD data points (difficult!). Further, we prohibit our agent to approach any OOD state-actions, while some of these might actually be good. Q-function networks do have the ability to generalize. It’s all about handling the uncertainty of these predictions. The agent might benefit from choosing some OOD data points which Q-values we can predict with high confidence. With SAC-N and EDAC An et al. (2021) found a way of effectively quantifying the Q-value estimates by an ensemble of Q-function networks. In this blog we will explore and explain them.
The Basics
Q-Learning
Like in standard reinforcement learning we want to find a policy \(\pi(a | s)\) that maximizes the cumulative discounted reward \(\mathbb{E}_{s_t, a_t}[...]\). The model-free Q-learning algorithm is a very common approach to learn the Q-function \(Q_{\phi}(s,a)\) with-in a neural network.
Actor-critic method
In the standard deep actor-critic approach we use two networks: (1) a policy-based actor network and (2) a value-based critic network.
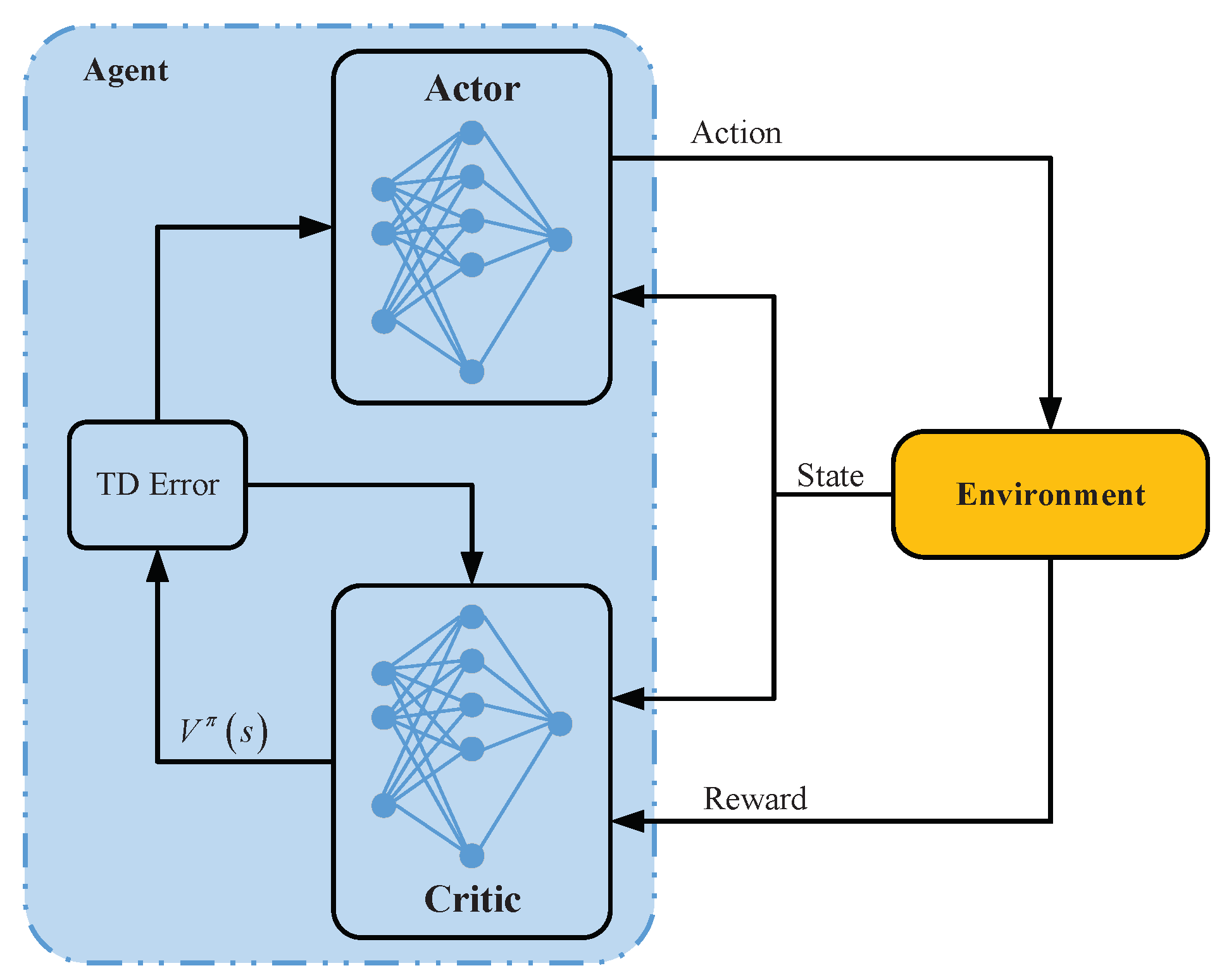
The critic network minimizes the Bellman residual. Note: In offline RL transitions are sampled from a static dataset \(D\)
\[J_q(Q_\phi) := \mathbb{E}_{(s,a,s') \sim D} \left[ \left( Q_\phi(s,a) - \left ( r(s,a) + \gamma\ \mathbb{E}_{a'\sim\pi_\phi(\cdot|s')}[Q_{\phi'}(s',a')] \right)\right)^2 \right]\]
The actor network is updated in an alternating fashion to maximizes the expected Q-value.
\[J_p(\pi_\phi) := \mathbb{E}_{s\sim D, a\sim\pi_\phi(\cdot|s)} \left[ Q_\phi(s,a) \right]\]
Conservative Q-Learning
As of 2021, Conservative Q-Learning (Kumar et al. 2020) is the state-of-the-art for offline RL. It uses a “simple Q-value regularizer” to prevent the overestimation of OOD actions.
\[\min_\phi J_q(Q_\phi)+\alpha(\mathbb{E}_{s\sim D, a\sim\mu(\cdot|s)}[Q_\phi(s,a)] - \mathbb{E}_{(s,a)\sim D}[Q_\phi(s,a)])\]
For each state, CQL computes a distribution over actions using a temperature parameter \(\alpha\) that controls the amount of exploration. The distribution is a mixture of the behavior policy and the current Q-function. The closer \(\alpha\) is to 1 the more conservative.
CQL will be used as the baseline.
Dataset
D4RL4 (Datasets for Deep Data-Driven Reinforcement Learning) is a collection of standardized benchmark datasets for offline RL algorithms. It includes a variety of environments but we focus on the MuJoCo Gym environments “Half Cheetah”, “Hopper”, and “Walker2D”.



Click to control a halfcheetah
Below you can interactively change the angles of the legs of the halfcheetah, similar to how the RL agents control them5.
MuJoCo stands for Multi-joint dynamics with Contact. It is a fast and accurate physics simulation engine for robotics, biomechanics, and others. The environments are stochastic in terms of their initial state, with a Gaussian noise added to a fixed initial state in order to add stochasticity. Goal in the gym tasks is, to run as fast as possible to the right by applying a torque on the joints. A negative reward is allocated for moving backwards. The observation space consists of body/joint position and velocity, while an action represents the torques applied between links.
As an example, the half cheetah environment has 6 joints and therefore a 6 dimensional action space which can be controlled using the inputs from a 17 dimensional observation space.
The data is collected by training an SAC algorithm online until it reaches a certain performance level (medium or expert). Then this strategy is used to collect 1 millionen samples of data. In the full-replay dataset the training data is collected as well.
Soft Actor-Critic (SAC-N)
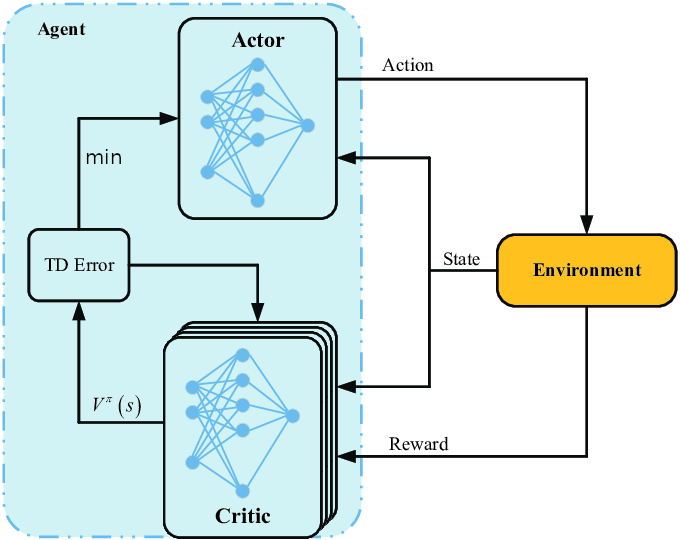
The paper introduces two new methods for offline RL. The first method is called SAC-N and is an extension of Soft Actor-Critic (SAC) (Haarnoja et al. 2018), which is a popular off-policy actor-critic deep RL algorithm. SAC-N extends SAC by using the q-value of N instead of two q-functions, i.e. critics, as visualized in #fig-actor-critic-sacn. The q-values are then reduces to a single value by taking the minimum. The idea behind taking the minimum of more critics is that the resulting q-value is more pessimistic when the uncertainty is high. This prevents erroneously high q-values of OOD actions and therefore trains the actor to prefer safer actions.
The minimum of multiple critics approximates the true q-value minus a multiple of the standard deviation (An et al. 2021):
\[ \mathbb{E}\left [\min_{i=1,...,N}Q_i\right] \approx m - \Phi^{-1}\left(\frac{N-\pi/8}{N-\pi/4+1}\right) \sigma \]
Where \(N\) is the number of critics, \(Q_i\) is the q-value of the \(i\)-th critic, \(m\) is the theoretical true q-value, \(\Phi\) is the CDF of the standard gaussian distribution, and \(\sigma\) is the standard deviation.
This is visualized in the diagram below, where q-value estimates over an exemplary action space are plotted.The black line is the theoretical true q-value and the grey area its standard deviation. The lightblue lines represent the critics, that try to approximate the true q-value. The bottom blue line is the minimum of the critics, that should, especially for a high number of critics, be roughly the true q-value minus a multiple of the standard deviation. You can use the slider to change the number of critics:
SAC-N already achieves notable performance and beats the previous state of the art, CQL, as will be shown in the results section. However, SAC-N requires a large number of critics, which comes with a high computational cost. Therefore, the paper introduces a second method, EDAC, that is more efficient.
Ensemble-Diversified Actor Critic (EDAC)
An et al. (2021) found, that the performance of the policy learned by SAC-N decreases significantly, when the q-functions share a similar local structure. To reduce this, they introduce an ensemble gradient diversification term to the loss function of the ensemble of critics:
\[ \underset\phi{\text{minimize}}\ \ \frac{1}{N-1} \sum_{1\leq i\neq j \leq N} \langle \nabla_a Q_{\phi_i}, \nabla_a Q_{\phi_j} \rangle \]
It measures the cosine similarity between the q-function gradients and is minimized when the gradients for the critics are as different as possible. This, in turn, leads to a more diverse ensemble of critics, which is more robust against overestimation of OOD actions.
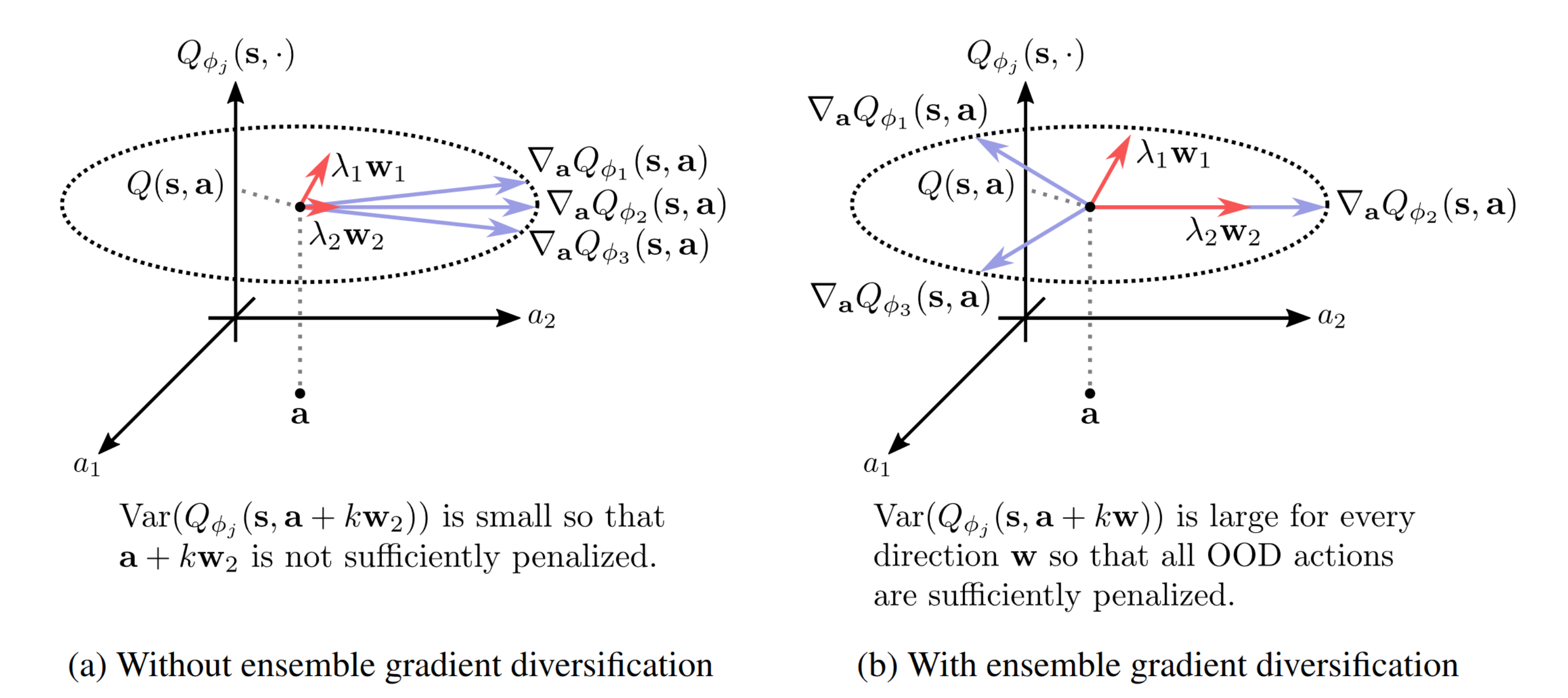
The full loss function of the critics is then:
\[\nabla_{\phi_i} \frac{1}{|B|} \sum_{(s,a,r,s')\in B} \left (\left( Q_{\phi_i}(s,a) - y(r, s') \right)^2 + \frac{\eta}{N-1} \sum_{1\leq i\neq j \leq N} \langle \nabla_a Q_{\phi_i}, \nabla_a Q_{\phi_j} \rangle \right)\]
where \(B\) is the batch of transitions, \(y(r, s')\) is the target q-function8, and \(\eta\) is the hyperparameter for how much the ensemble gradient diversification term should be weighted.
Note that EDAC reduces to SAC-N when \(\eta=0\).
Implementation
There are multiple implementations of EDAC and SAC-N available. An et al. (2021) published their implementation on GitHub. It contains 9712 lines of python code over 93 files.
Another implementation is part of the Clean Offline Reinforcement Learning (CORL) Repository, which aims to provide single-file implementations of SOTA offline RL algorithms. Its EDAC implementation contains 639 lines of code in a single file. This makes it significantly easier to understand and modify. We therefore used it for some of our experiments and as a inspiration for our own implementation.9
We also implemented EDAC from scratch in PyTorch and managed to achieve a code size of 379 lines, while adding additional features10. Our results below are based on our implementation until stated otherwise.
Code
A simplified version of the main parts of our train function looks like this:
def train(config, ...):
# initialize environment, and set seeds
...
# initialize models
actor = Actor([state_dim, 256, 256, action_dim], ...)
critic = VectorCritic([state_dim + action_dim, 256, 256, 1], ...)
target_critic = deepcopy(critic)
log_beta = torch.tensor(0.0, requires_grad=True)
beta = log_beta.exp()
# initialize optimizers (Adam)
...
# set critic ensemble reduction function, by default `min`
...
# load checkpoint if given, save the config, and initialize logging
...
# main training loop
for epoch in range(config.epochs):
for step in range(config.updates_per_epoch):
# sample batch of transitions
state, action, reward, next_state, done = buffer.sample()
# calculate q-target
next_action, log_prob = actor(next_state)
q_next = (
critic_reduction(target_critic(next_state, next_action))
- beta * log_prob
)
q_target = reward + config.gamma * (1 - done) * q_next
# update critics
base_critic_loss = (critic(state, action) - q_target).pow(2)
q_gradients = torch.autograd.grad(critic(...), ..., create_graph=True)
diversity_loss = (q_gradients @ q_gradients.T) * (1-torch.eye(N)) / (N-1)
critic_loss = base_critic_loss.sum(-1) + config.eta * diversity_loss.sum(1,2)
...
# update beta
actor_action, actor_action_log_prob = actor(state)
beta_loss = (-log_beta * (actor_action_log_prob - action_dim))
...
beta = log_beta.exp()
# update actor
actor_q_values = critic(state, actor_action)
actor_loss = -(critic_reduction(actor_q_values) - beta * actor_action_log_prob)
...
# update target critic
for target_param, source_param in zip(
target_critic.parameters(), critic.parameters()):
target_param.data.copy_(
(1 - config.tau) * target_param.data
+ config.tau * source_param.data
)
# save checkpoint, and log metrics
...Which uses separate classes for the Actor and VectorCritic11:
class Actor(nn.Module):
def __init__(self, layer_sizes : list[int], ...):
...
# setup hidden layers based on the given layer sizes
self.hidden = nn.Sequential(*(
x for i in range(len(layer_sizes) - 2) for x in [
nn.Linear(layer_sizes[i], layer_sizes[i + 1]),
nn.ReLU()
]
))
# create output and output uncertainty layers
self.output = nn.Linear(layer_sizes[-2], layer_sizes[-1])
self.output_uncertainty = nn.Linear(layer_sizes[-2], layer_sizes[-1])
# init parameters as in the EDAC paper
...
def forward(self, state):
x_hidden = self.hidden(state)
x_mean = self.output(x_hidden)
x_std = torch.exp(torch.clip(self.output_uncertainty(x_hidden), -5, 2))
policy_dist = Normal(x_mean, x_std)
action_linear = policy_dist.rsample()
action = torch.tanh(action_linear) * self.max_action
action_log_prob = policy_dist.log_prob(action_linear).sum(-1)
return action, action_log_probVectorCritic(nn.Module):
def __init__(self, layer_sizes: list[int], num_critics: int):
...
# create multiple critics with the architecture given by layer_sizes
# the output layer has no activation function
self.models = nn.ModuleList([
nn.Sequential(*[
x for i in range(len(layer_sizes) - 1) for x in [
nn.Linear(layer_sizes[i], layer_sizes[i + 1]),
nn.ReLU()
]
][:-1]) for _ in range(num_critics)
])
# init parameters as in the EDAC paper
...
def forward(self, state, action):
return torch.cat([
model(torch.cat([state, action], dim=-1)) for model in self.models
], dim=-1)We used pyrallis for the configuration and command line interface, and Weights & Biases for tracking our experiments.
Modifications
We made a few modifications to the EDAC algorithm described in the paper.
Dynamic \(\beta\)
As can be seen in the train function above, \(\beta\) (beta) is learned dynamically during training. While this is not explicitly mentioned in the pseudocode in the paper, the official implementation uses it, if use_automatic_entropy_tuning is set to True. As it can significantly improve training speed and the performance of the actor (at least for a limited training time), we decided to use it as well.
However, we found that sometimes \(\beta\) would decrease continuously, which also limits the performance of the actor. How to prevent this could be a topic for future research.
Alternative Critic Ensemble Reduction
SAC-N, and therefore also EDAC, use the minimum q-value estimate of their critic ensembles. However, it seems like this could be too pessimistic in some cases, as q-value estimates cannot only be erroneously high, but also erroneously low. We tried to get better q-value estimations by subtracting a multiple of the standard deviation \(\sigma\) from the mean \(\mu\), i.e. \(Q_{\text{final}} = \mu - \alpha * \sigma\), where \(\alpha\) is a hyperparameter12. The idea is to be more pessimistic, the higher the standard deviation is. Actually, as already mentioned in the section about SAC-N, this should be the expected value of the minimum q-value estimate for some specific \(\alpha\) and therefore be similar. However, as can be seen below in Figure 11, it performs significantly worse than the minimum.
Alternative critic ensemble reduction functions could be based on the median or use a weighted average of the q-values, where the weights decay exponentially for higher q-values. This, too, could be a topic for future research.
Results


The learning curve is similar for all batch sizes. With n=2048 we have optimal performance. Note: In the paper they had batch size n=256 although they used the same graphics card.
Interpretation: Our implementation performs best on the full-replay dataset. From mistakes made during training the model can learn. The full replay has the best mix between these errors and good actions. This way there are less OOD actions. Problem: The model should be able to learn from biased data, especially from expert data. It is possible though, that training with the expert dataset just needs much more time to kickstart.
Interpretation: EDAC with only 10 critics can outperform SAC-20. Increasing \(N\) did not always improve the results for EDAC. The training duration is heavily dependant on the amount of critics.

Interpretation: Using a custom critic reduction instead of the minimum, did not work with EDAC. The standard deviation of the ensemble might fluctuate too much to be “contained” by a static parameter. Other approaches could be to try out this method with SAC-N. Another idea is to take the median instead of the mean.
Videos
Conclusion
Offline RL avoids failure during training, as the agent doesn’t have to interact with the environment. SAC-N and especially EDAC, as proposed by An et al. (2021), achieve convincing results on MuJoCo Gym tasks by penalizing actions with uncertain q-values using an ensemble of critics. We managed to implement EDAC in a relatively concise way, and were able to reproduce the high scores of the paper in some tasks. To train more efficiently, we found a batch size of 2048 to work well, and that a too high number of critics can also decrease performance. While trying custom critic ensemble reduction functions, we found that the minimum is the best choice among the tested, while proposing directions for future research. We also found dynamic training of \(\beta\) to be beneficial, but encountered instabilities. As the used tasks are relatively simple and narrow in scope, it would be interesting to see how EDAC performs on more complex tasks and in real world environments.
Overall, EDAC seems to be a promising approach to train offline RL agents, but further evaluations and improvements are needed for its use in real world applications.
Acknowledgements
This blog post was created for the Advanced Topics in Reinforcement Learning seminar (2022/23) at TU Berlin. We would like to thank Dr. Rong Guo for supervising this seminar.
The code for this blog is available on GitHub.
References
Agarwal, Rishabh, and Mohammad Norouzi. n.d. “An Optimistic Perspective on Offline Reinforcement Learning.” Google AI Blog. https://ai.googleblog.com/2020/04/an-optimistic-perspective-on-offline.html.
An, Gaon, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. 2021. “Uncertainty-Based Offline Reinforcement Learning with Diversified q-Ensemble.” In Neural Information Processing Systems. https://arxiv.org/pdf/2110.01548.pdf.
Fu, Justin. 2020. “D4RL: Building Better Benchmarks for Offline Reinforcement Learning.” Berkeley Artificial Intelligence Research. https://bair.berkeley.edu/blog/2020/06/25/D4RL/.
Giang, Hoang Thi Huong, Tran Nhut Khai Hoan, Pham Duy Thanh, and Insoo Koo. 2020. “Hybrid NOMA/OMA-Based Dynamic Power Allocation Scheme Using Deep Reinforcement Learning in 5G Networks.” Applied Sciences 10 (12). https://doi.org/10.3390/app10124236.
Haarnoja, Tuomas, Aurick Zhou, P. Abbeel, and Sergey Levine. 2018. “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor.” In International Conference on Machine Learning. https://arxiv.org/pdf/1801.01290.pdf.
Kumar, Aviral, Aurick Zhou, G. Tucker, and Sergey Levine. 2020. “Conservative q-Learning for Offline Reinforcement Learning.” ArXiv abs/2006.04779. https://arxiv.org/pdf/2006.04779.pdf.
Footnotes
This is only a rough approximation to how the halfcheetah environment works. One of the main differences is that the agents control the torque on the joints instead of the angle.↩︎
Using target critics / q-functions can help to reduce instabilities during training. For more details, you can read the code under Implementation↩︎
Our fork of CORL for our experiments is also available on GitHub↩︎
We added features like the continuation of training runs, and new critic ensemble reduction functions (instead of min) to our implementation.↩︎
The
VectorCriticis a wrapper around a list of critics, which simplifies the handling of multiple critics.↩︎In our implementation this can be set with e.g.
--critic_reduction=mean-4.2for \(\alpha=4.2\)↩︎