There is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning
Introduction
Making reinforcement learning safer has two benefits, namely lower-risk exploration (mostly relevant in real-world tasks), and more efficient learning. As the agent spends more time in safe states, it will more likely reach states with positive rewards and find a optimal solution. There are many ways to tackle this problem of safety, with the "There is No Turning Back"-paper by Nathan et. al. [1], published at the NeurIPS 2021 taking a very interesting approach. There assumption is simply this: If something is reversible, it must be safe, since the agent can always return to where it was safe. The authors further find some very interesting ways to implement this assumption in reinforcement learning. They successfully proof, that reversibility does indeed hold information about the environment, and that this information can be leveraged to create safer and more efficient learning and exploration.
Method
Reversibility is difficult. Still, we understand it intuitively. I lift my tea cup: reversible. I throw the same cup out of the window: not reversible. But why? Surely the cup could be fixed. Just that its super complicated and no one would bother. And that's the thing: Super complicated, no one would bother.
Reversibility then means getting back to the start is about as simple as getting to the result. In other words, start and result are interchangeable. Or in mathematical terms: Reversibility means a transition between both states is equally likely. And if that likelihood can be predicated, we have a functional reversibility estimator. This is the basis of the paper, which they go on defining mathematically.
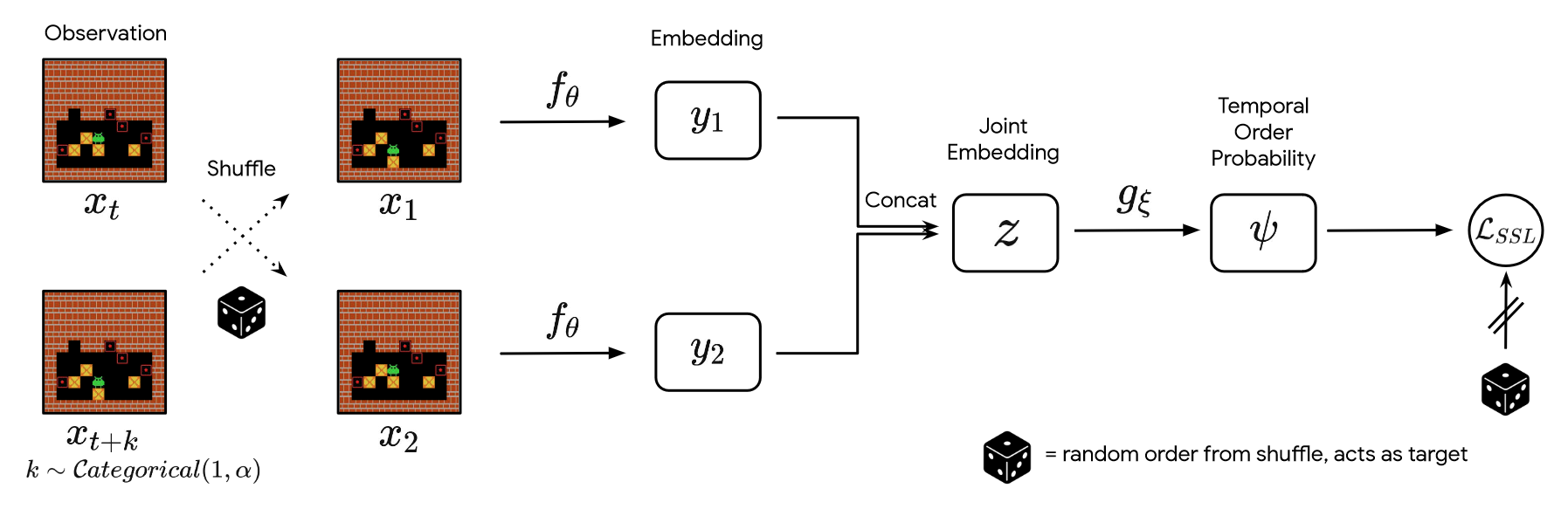
Mathematical Reversibility and Reversibility Estimation
Finding a mathematical expression for reversibility is surprisingly simple (At least if we leave out a few proofs along the way...). What we want to show is this: Starting at state s and performing action a, how likely is it, that we will eventually return to state s? We call this reversibility, and can define it like so:
Infinity is luckily not necessary for interaction with most environment, so let's instead reduce that to K steps:
That's better, but would still mean sampling all possible trajectories after action a in state s. Probably not feasible. We are still not working with our initial statement though. Remember? Reversibility means a transition between both states is equally likely. There therefore exist a much simpler question: Could the result have been before? In the paper, this concept is called precedence, and they define it like so:
Read: "For two states s and s' from a trajectory τ with length T in a given policy π at the timesteps t and t', which timestep is greater?" Precedence will therefore be 1 if state s always comes first, and 0 if state s never comes first. Using this, we can ask: How likely is it that state s' comes before state s, when s' is a result of taking action a in state s? If it is 1, the transition from state s to state s' must be reversible. This is called empirical reversibility:
Finally, we can connect the reversibility and the empirical reversibility like so:
As the mathematical proof is rather long, we will skip it. What matters is that if the empirical reversibility is small, the true reversibility is even smaller. Meaning everything with a small empirical reversibility should always be avoided. Makes sense, right? This does, of course, imply, that if the empirical reversibility is 1, the true reversibility could still be 0, which seems like somewhat of an oversight.
On the other hand, the actual method only relies on precedence, which, to me, requires no further proof via reversibility. Of course it makes sense to tie the paper to the initial claim of reversibility, but as mentioned, reversibility is difficult to define. This is why even semantically, moving to precedence makes sense. Therefore, analytically trying to return to the already ill defined concept of reversibility seems redundant, if not impossible.
Therefore: No more math, and on to the algorithms! 🐱🏍
Algorithms
Two methods of using reversibility are defined in the paper: Reversibility-Aware Exploration (RAE) and Reversibility-Aware Control (RAC). As this paper is all about reversibility-awareness, we'll just call them exploration and control.
Exploration, in general, means an agent is still actively learning about it's environment. Reversibility should therefore not be a limit, but instead a guide. This guide, as all things RL, is expressed as a reward. Meaning if an action seems highly irreversible, a slight penalty will be added to the returned reward.
Control on the other hand aims at clearly limiting the agents actions. Here, any action that does not seem sufficiently reversible, gets rejected, and the agent has to sample from the remaining actions.
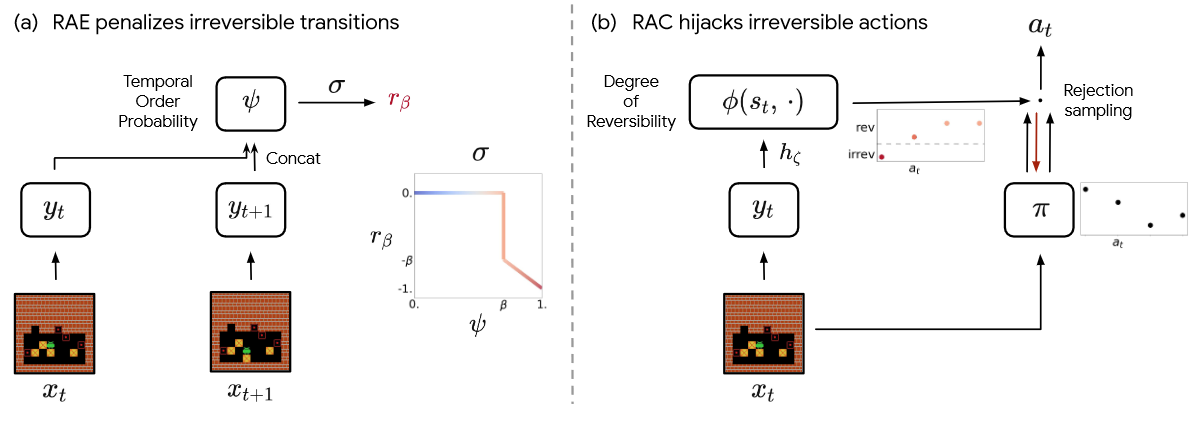
Reversibility-Aware Exploration
As mentioned, RAE provides a penalty for irreversible actions. To decide if an action is irreversible, we set a threshold β∈[0, 1], and only apply a penalty if our reversibility is below this threshold. We get this reversibility value via a neural network. This network is trained on pairs of observations with a pre-defined maximum distance. These two observations are shuffled, embedded, and then trained on. Given enough samples, the neural network can confidently predict if the second observation could ever happen before the first. This is what we previously defined as precedence, or the temporal order probability. As this values is between 0 and 1, we can directly compare it with the threshold and penalize the reward accordingly.
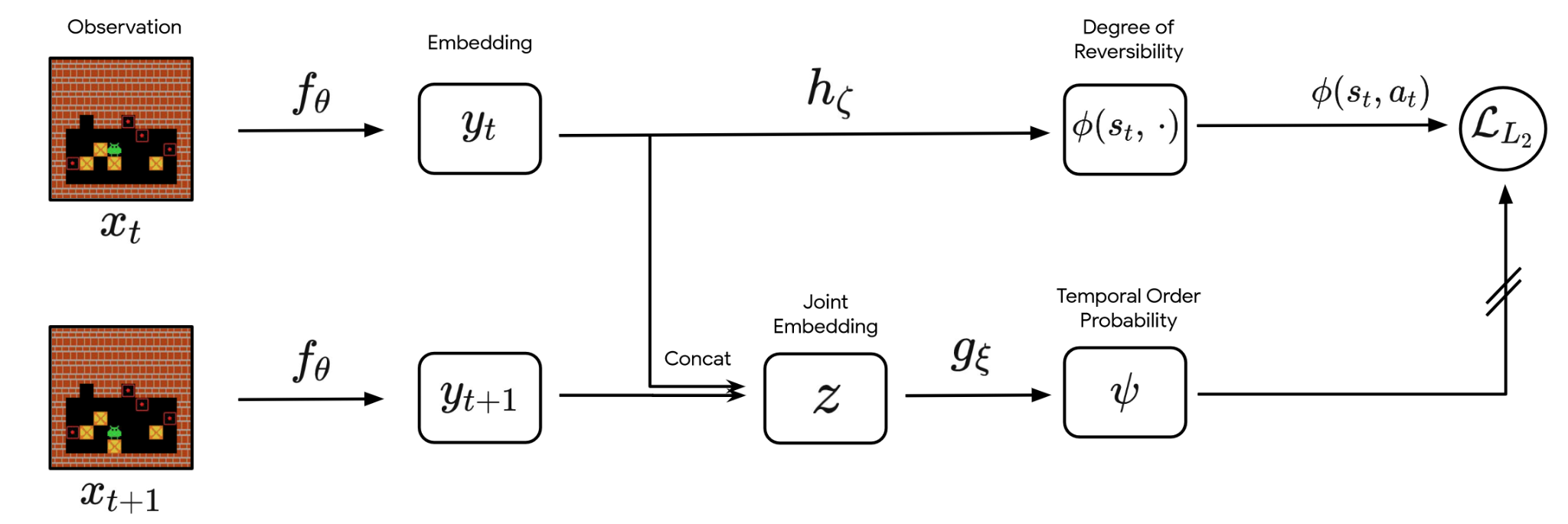
Reversibility-Aware Control
RAC on the other hand aims to make predictions about actions before they happen. To do this, it trains a second neural network using the predicted temporal order probability as targets. Basically, it predicts using its own predictions as a target while changing to a different input. This new input is the original state s as well as the chosen action a (instead of the state s and s' like in RAE). Given enough samples, the second neural network, or action network, can then predict if an action results in a reversible state. Should this probability be below a certain threshold, the action is rejected, and a new action must be sampled. RAC is trained on offline data of the environment to ensure safety during the online training.
Implementation
RAE should, in theory, provide a safer, and, if the environment benefits from avoiding irreversible states, more efficient exploration of the environment. This is first tested by disabling the rewards in the Cartpole environment (see Reward-Free Reinforcement Learning) to show that a policy avoiding irreversible states can still be learned with just the feedback from RAE.
Further, REA is deployed on two different environments with the rewards enabled (see Reversible Policies and Sokoban) to show that the exploration of the environment becomes safer and more efficient.
Finally, RAC is used to create completely Safe Policies using offline data gathered via random exploration.
I have tested some of the algorithms, with my results added below when available. All my implementations are based on the author's GitHub [2].
Reward-Free Reinforcement Learning
For the initial test is on the Cartpole environment, the reward was removed, and feedback for the PPO agent was only provided via penalties based on RAE predictions. These are the papers results:

Most relevant here is the left plot, showing the agents performance (blue) and the feedback provided by RAE (red). As RAE needs to first learn which states are irreversible, it initially provides no sensible feedback. Once the feedback becomes less random, the agent improves rapidly, until the Cartpole environment is solved. They further show RAE predictions based on pole coordinates and during two trajectories, with red indicating irreversibility and blue indicating reversibility. These results are pretty much what we would expect, with an upright position being fairly safe, while tilted positions are assumed more irreversible.
Here are my results:
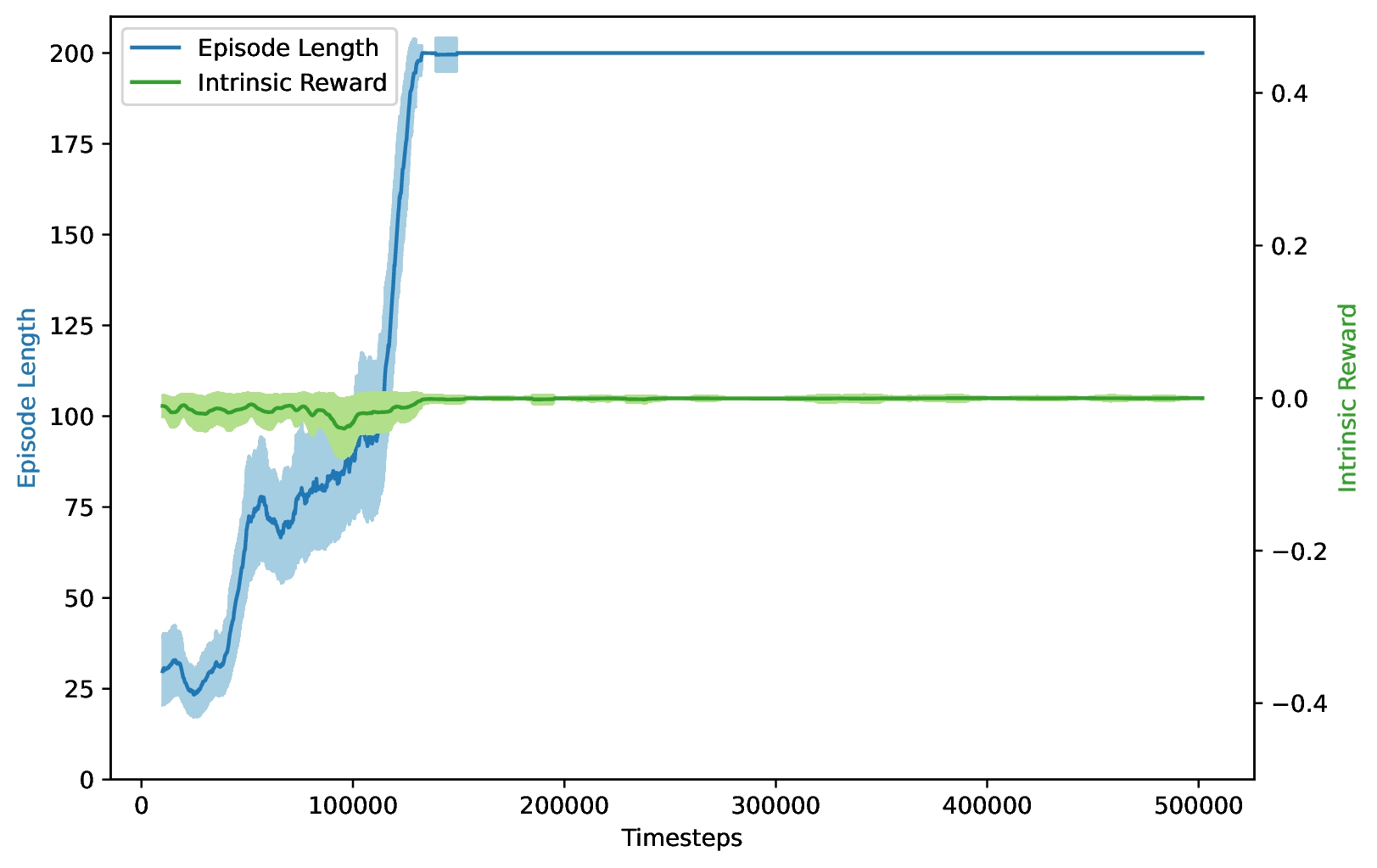
And a little more readable when plotted over Epochs:
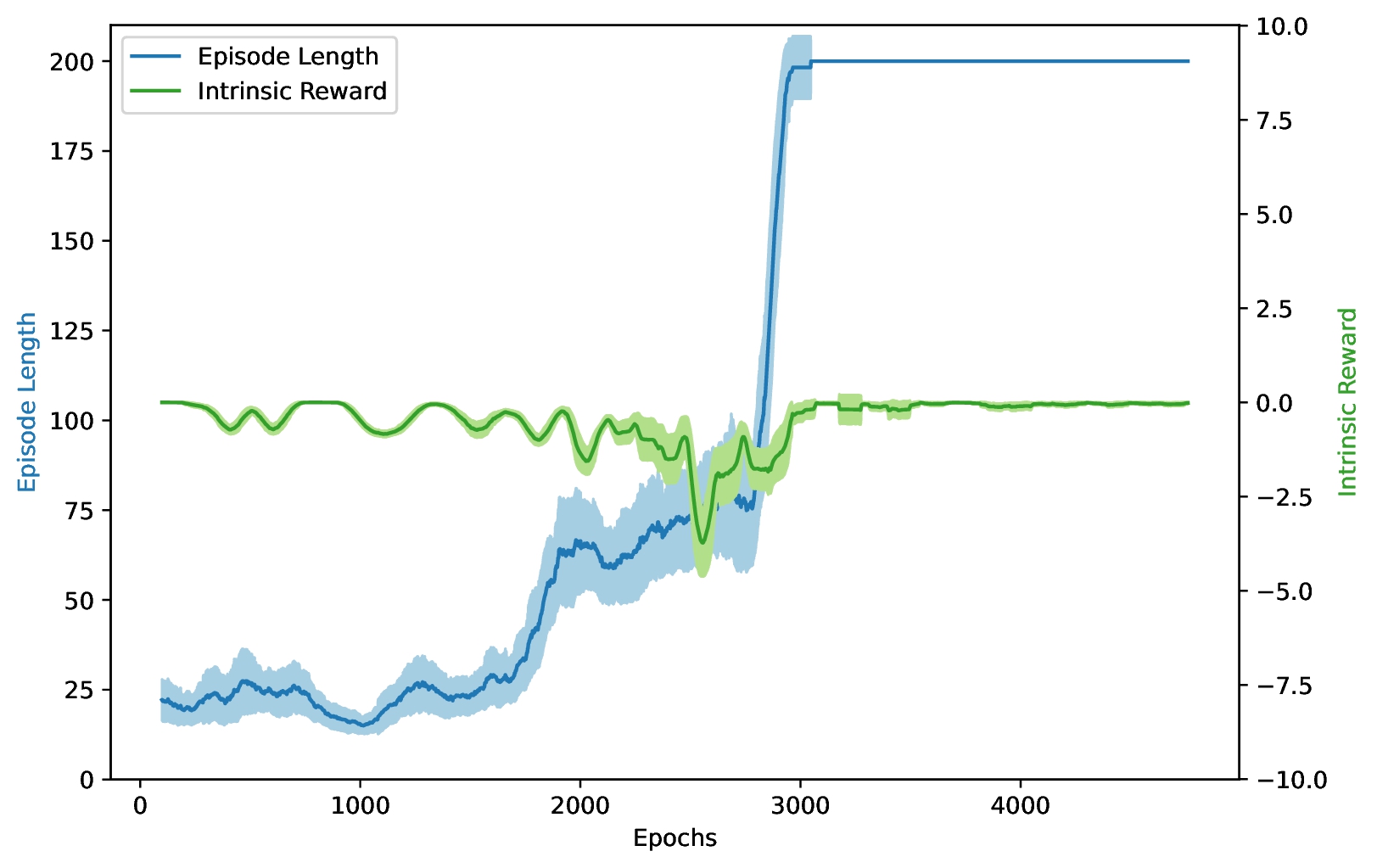
Nothing to add, really. Mine doesn't look as smooth, and I think the label "Reward-Free" is a little misleading, but the algorithm works as expected. Moving on.
Reversible Policies
Now this is an odd one. First, the environment [1]:

This is the Turf environment, as proposed by the authors. The agent (blue) must reach the goal (red). If it leaves the path (grey) and steps on the grass (green), the grass will turn to dirt (brown). This is not punished, but it is irreversible. Using RAE, the agent should therefore learn to avoid the grass and stay on the path, automatically creating a reversible policy. Here are their results (blue indicates a higher visiting rate) [1, p.8]:
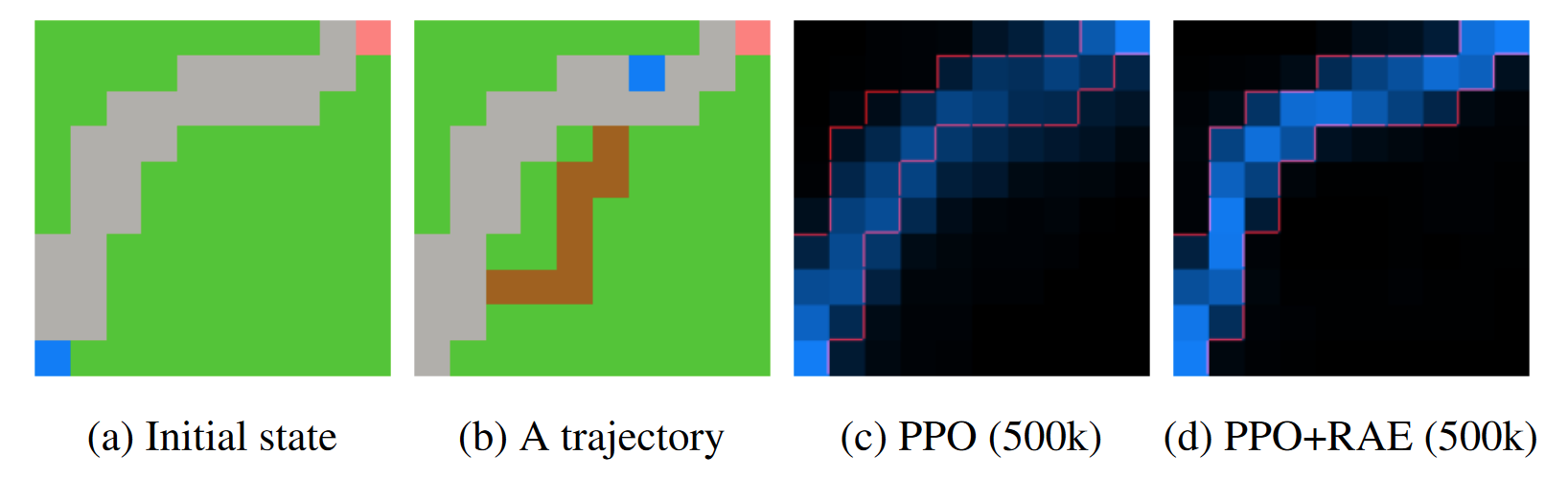
Avoidance of the grass does indeed happen, but as can already be seen in their results, it also happens without RAE. Here are my results (yellow indicates a higher visiting rate):


See the difference? Me neither. (PPO is left, PPO+RAE is on the right). To ensure I am not just bad at seeing colors, here is the spoiled grass by both algorithms over time:
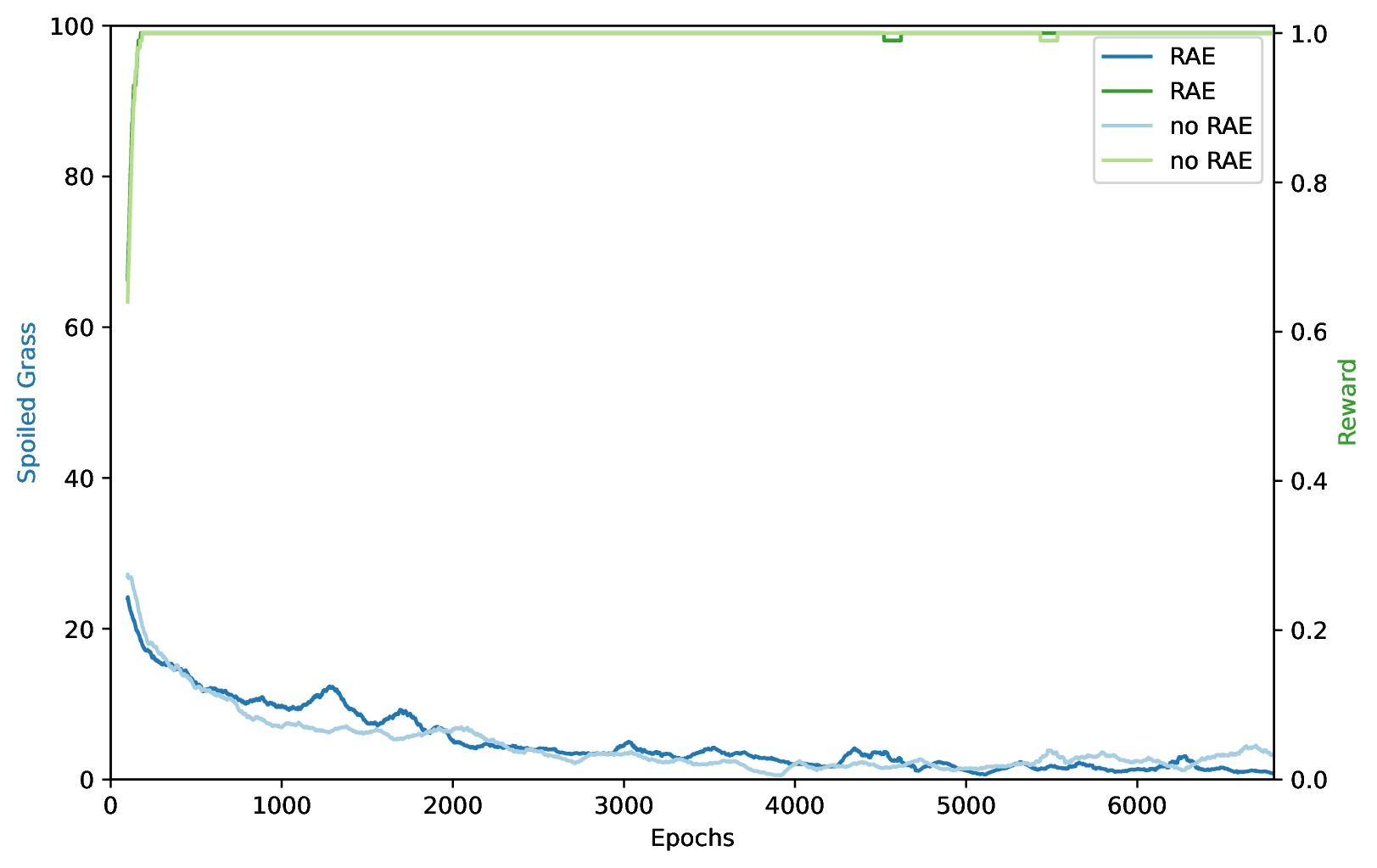
Again, no real difference. My guess is PPO already avoids the grass on its own. As diagonal movements are not possible, any trajectory containing only the moves up and right will be optimal. Therefore, sticking to the path probably helps finding the way, which is why PPO learns this behavior, even without RAE.
Sokoban
Sokoban (image on the left) then is a lot more interesting. The environments aim is for the agent (green alien) to push the orange boxes on the positions marked in red. Pushing any box up to a wall can make solving the environment impossible, but does not result in a fail state. Agents can therefore collect a lot of useless data, making training extremely inefficient.
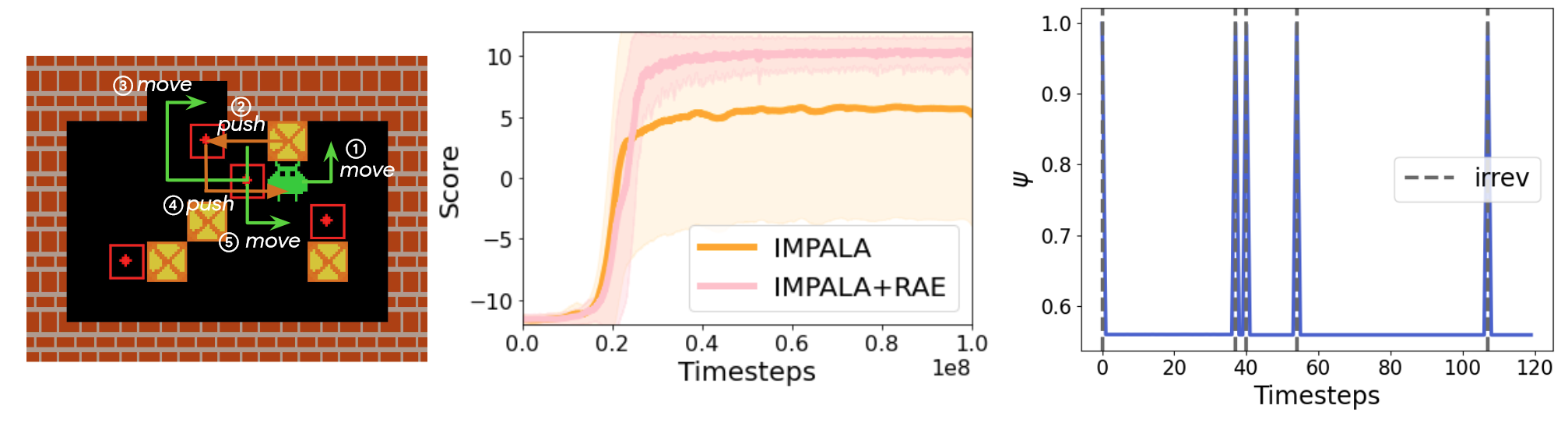
As they show, adding RAE makes training more effective, with the algorithm being able to solve the environment much more consistently then a pure IMPALA implementation. The plot on the right shows the frequency of irreversible states, showing that RAE is able to learn reversibility sufficiently, even though it is an overall very sparse event.
Due to the training taking about a week on my hardware, I could not confirm their results and can't really add anything. I'm surprised that, even though the environment seems so complicated, irreversible states are so rare. Maybe the initial levels are comparably easy.
Safe Control
Cartpole+:
For safe control, they first tested on a cartpole environment with a maximum step size of 100.000 (meaning the episode can be 500x longer than normal cartpole). A random policy initially collects offline data (3 Million pairs to be exact), RAC trains on this data, then a random policy is deployed, with RAC removing irreversible actions.
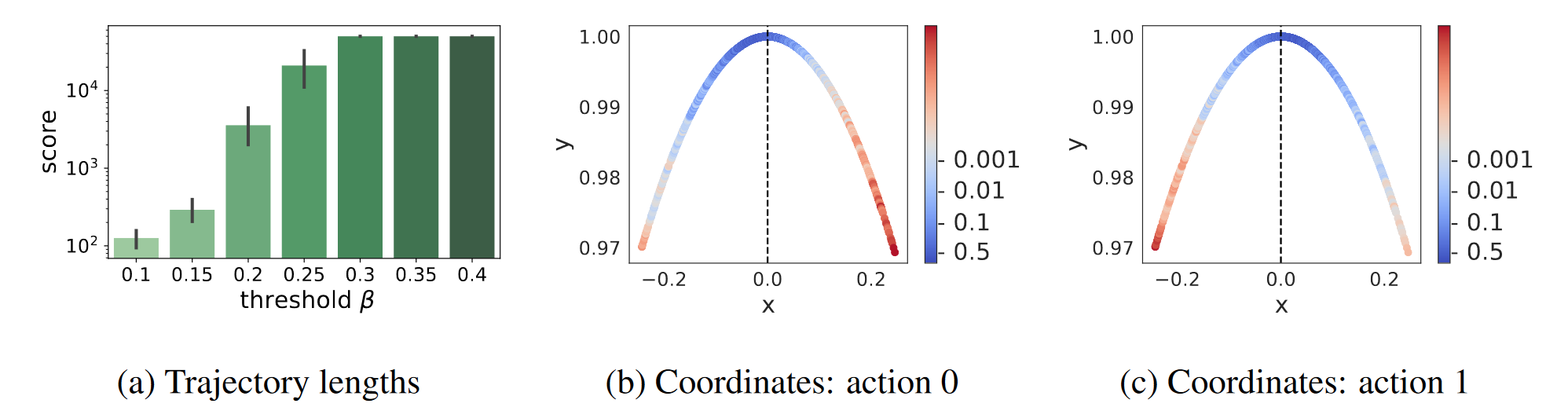
Their results show that this works, but performance seems highly dependent on the choice of the threshold for reversibility (plot on the left). To find the correct threshold they suggest selecting 0.5 and inclemently reducing it. This could be problematic, but also isn't (I'll get to that in a second). For now, here are my results:
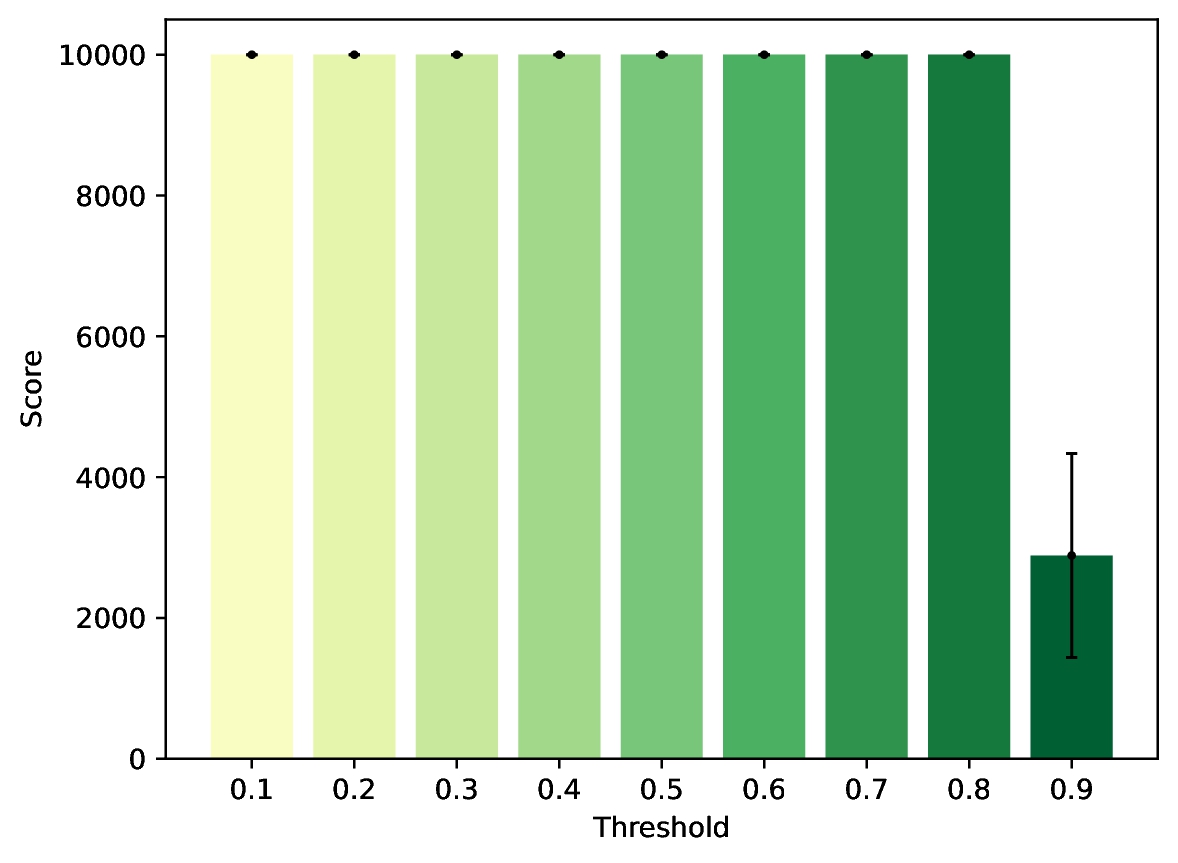
Yes, they are reversed. I'm assuming they implemented it with rejecting actions above the threshold for some reason, while both paper and their code reject actions below the threshold. Beyond that, results are similar, although I stopped my environment at 10.000 steps due to the long time the tests would otherwise take. Now before we get back to why all threshold should have similar results, I want to emphasize something: RAC does not automatically turn randomness into a good policy. Cartpole only has two actions, therefore removing an irreversible action always only leaves the optimal action. If the environment had 10 available actions, of which RAC removes, say, 3, behavior would still be random within these 7 actions.
Okay, so what about the threshold? The RAC model is the same in all tests, so why does changing the threshold make the performance worse? So again, this is something very unique to Cartpole, as it only has two actions. Any higher action space would definitely have to consider the threshold very carefully. The issue in Cartpole only arises when both actions cannot clear the threshold. A logical behavior would then be:
A: Choose the action with the highest reversibility value.
B: Implement a dynamical threshold.
C: Do nothing.
Here is how A performs:
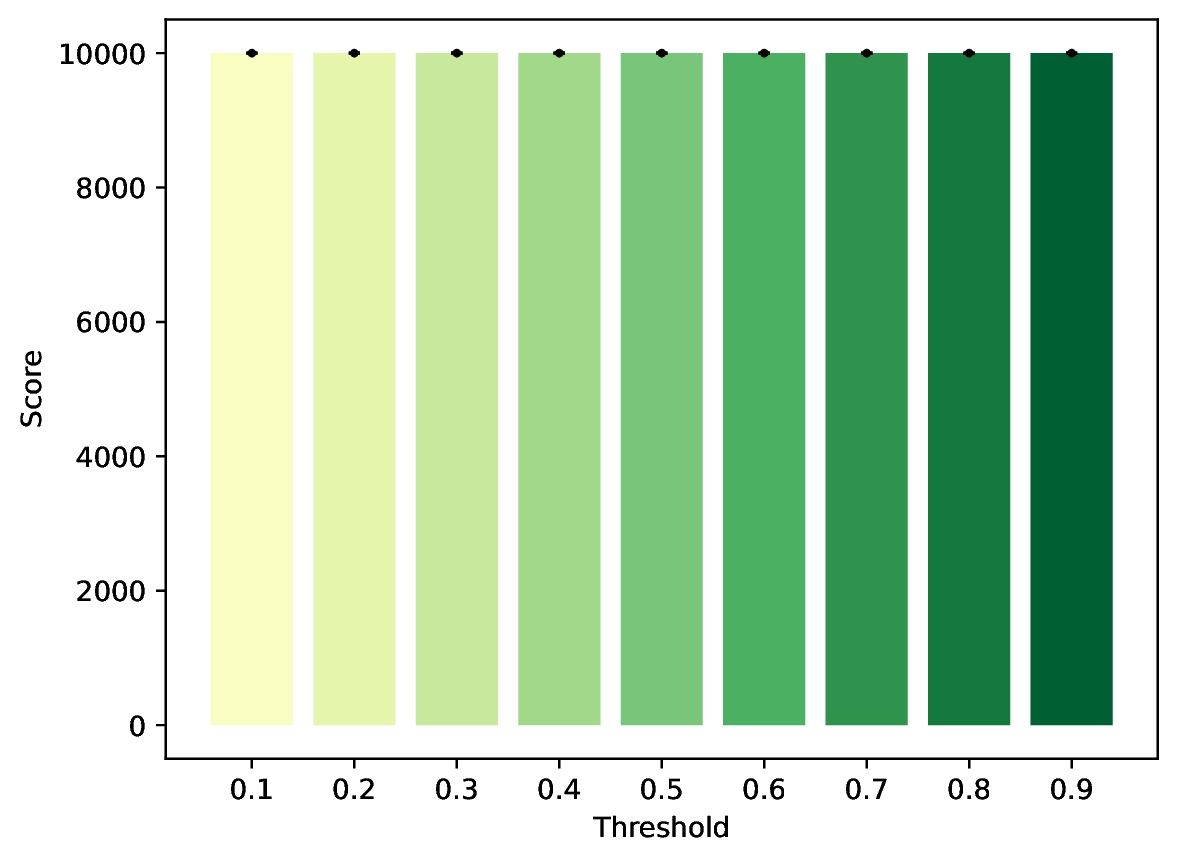
Granted, this theoretically turns the RAC into a action predictor, which according to the initial math section is not within the scope of it's design. What I am only trying to point out is that the possibility for no action to clear the set threshold always exists, and is not addressed by the authors.
Turf:
Finally: Turf again, this time with RAC. Training is again done using offline data created via a random policy. They show that using RAC, the PPO agent trains slightly slower (initially it never reaches the goal), but never ends up stepping on grass.
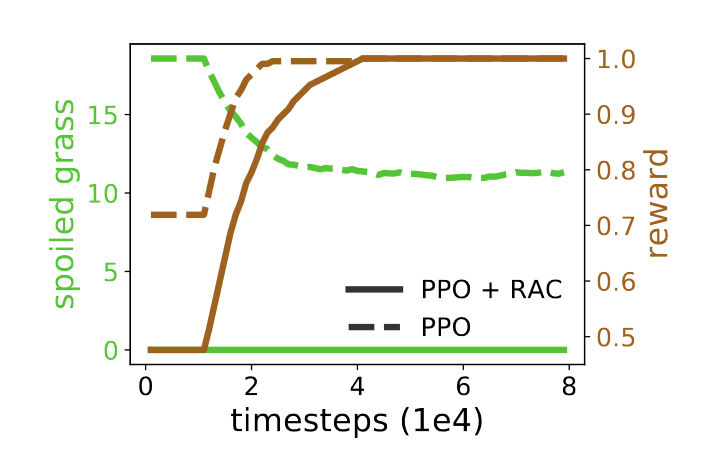
Here are my results, using the values they provided (β=0.2):

Wait, I'll explain. So, the agent assumes everything is irreversible except when it is super, super reversible. Like standing still. Of course the agent can't stand still, so instead it moves either down or to the left. Basically, when being told to move, to stay safe it decides to consistently move against a wall. I think this is what they were really trying to show in the Cartpole+ example. The threshold really matters. As mentioned earlier, their implementation of the threshold seems to be aiming for above the threshold, not below like in their GitHub. Here it is again with β=0.8:

Look, sue me. I have no idea what this agent is doing. Obviously not following the path. I tested this repeatedly, with varying results, but nothing similar to theirs. My guess is some relevant hyperparameters are wholly different from their implementation. I am sure their results are not made up, but this seems to really require a lot of fine-tuning (and maybe even the correct seed) to get right.
Tests
During my reading of the paper as well as of the notes provided by reviewers, three potential problems showed up:
The algorithm could be used to enforce irreversibility.
Predicting on state transitions leads to high computational time for larger state spaces.
Stochastic environments could be difficult for reversibility-prediction.
I have tested all three problems, and summarized my findings below.
Harmful Irreversibility
Using reversibility to enforce irreversible actions and cause harm seems to be simple enough, although the authors provide a somewhat handwavy explanation as to why this is not an issue. [1, p.10] In short: Yes, it can be used to take irreversible actions, but it can also be used to prevent that. (I'm paraphrasing.) This, obviously, is not a solid explanation, as it assumes that people without harmful intend have the final say about what the code does. Not only is this pretty much impossible to enforce (the paper is public after all), it also ignores the very real ability and creativity of people trying to hack systems to behave outside their intended purpose.
A very simple example would be as follows. Here is the original code they use during Safe Control on Cartpole+:
irrev_idx = rev_score[:, actions].squeeze(1) > thresholdif irrev_idx.sum() > 0: actions[irrev_idx.cpu().numpy()] = torch.argmin(rev_score[irrev_idx], axis=1).cpu().numpy()Here is my adjusted code:
xxxxxxxxxxirrev_idx = rev_score[:, actions].squeeze(1) < thresholdif irrev_idx.sum() > 0: actions[irrev_idx.cpu().numpy()] = torch.argmax(rev_score[irrev_idx], axis=1).cpu().numpy()The only changes are:
reversed relation operator at the end of the first line
argmax in the middle of the final line
Here is the new performance, using the same trained RAC network:
Not very nefarious, but clearly proves a point. With these changes, the agent will only chose actions with a reversibility score below the threshold, which, if trained properly and using the correct threshold, are always irreversible (at least if any irreversible actions are available).
Computational Time
Another relevant worry, as raised by one of the reviewers, is the computational time. As the implementation aims to predict reversibility from one state to another, and for n states exist n² different state-transitions, the computational time is O(n²). To test this, I set up a Turf world four times as large as their implementation (20x20).

I then ran a PPO agent with RAE on both, here are the results:
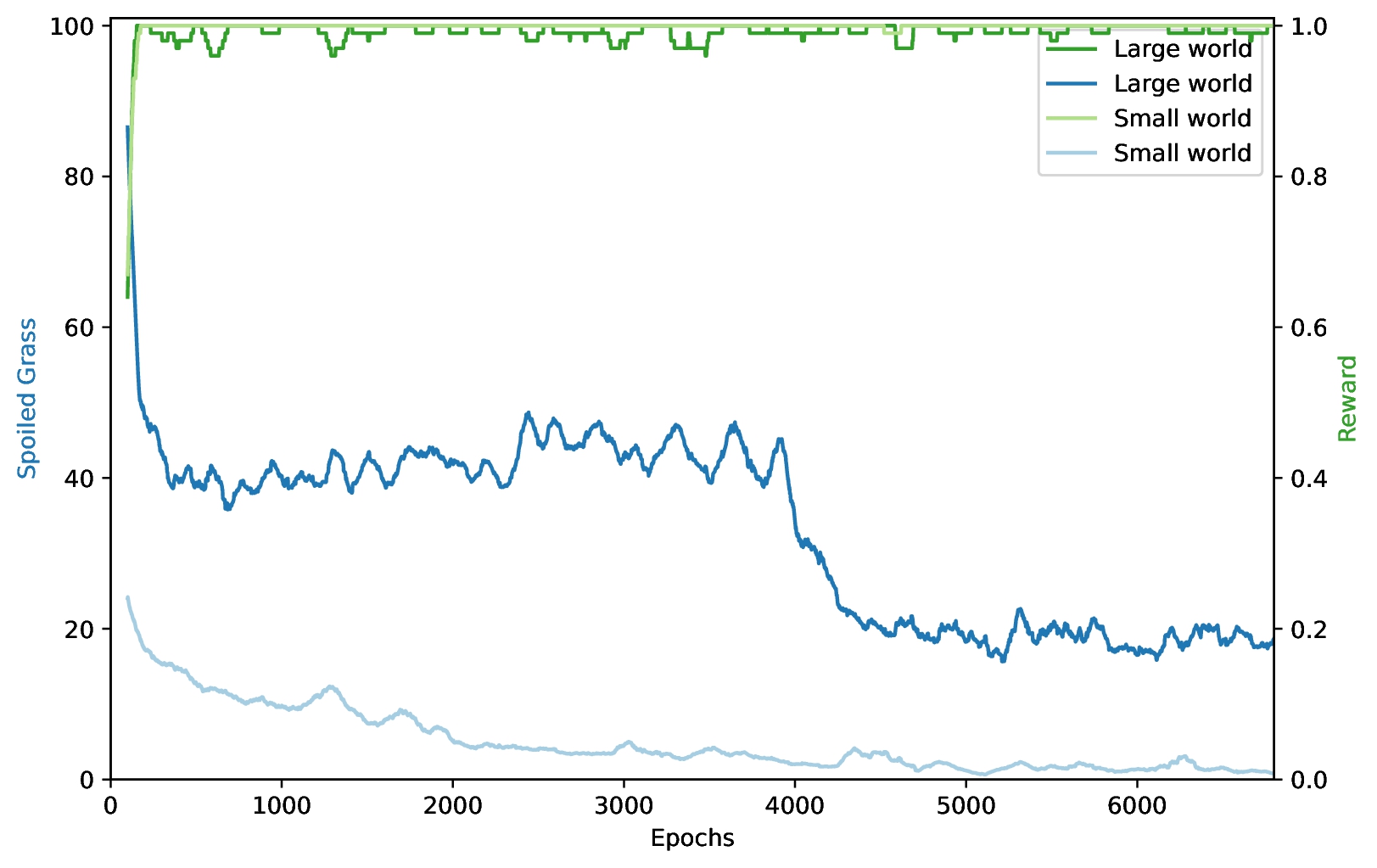
Okay, so on the larger world it performs worse, maybe not too surprising? Well, I did increase the maximum step count for the large world. Meaning even though both trained for the same amount of epochs, the larger world had at most likely ~4 times as much training time. Assuming linearity, performance should be roughly the same, especially considering the performance on the small world wasn't really increased by RAE. To make sure, I compared the performance of a pure PPO agent vs. a PPO+RAE agent on the large Turf world:
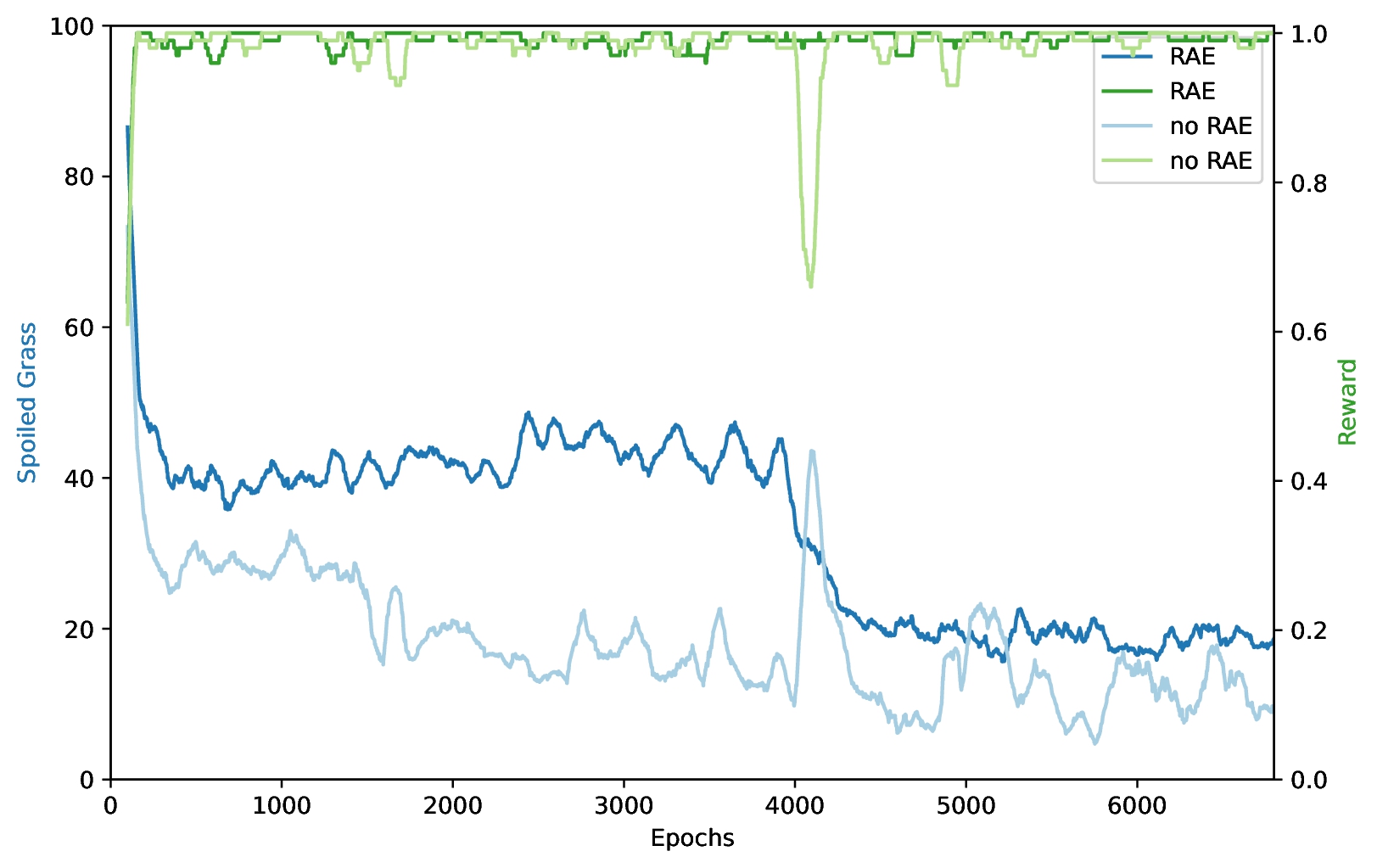
Turns out RAE actually makes the agents performance substantially worse at avoiding grass? This confused me so much I checked the whole code again and reran the test. Same result:
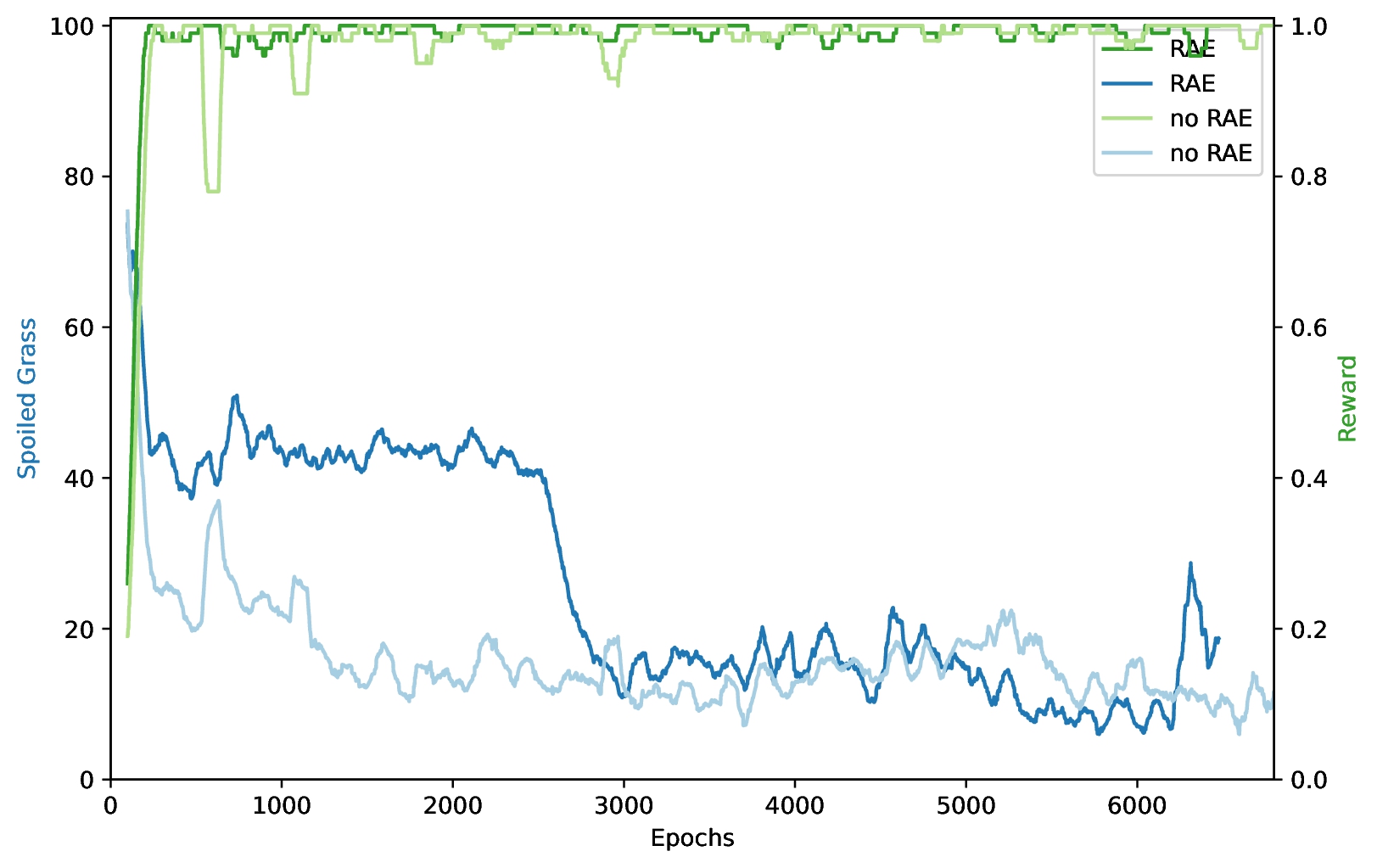
Interestingly though, both processes show the same significant drop in spoiled grass at some point in time. I am assuming that this drop happens, when the RAE neural network finally learns to make reasonable predictions for reversibility. With penalties before the drop therefore being somewhat random, the agent most likely doesn't create an efficient policy and ends up taking longer to reach the goal. It thereby will probably step on more grass along the way, and when compared to pure PPO starts underperforming. This doesn't sufficiently proof computational time issues, but does show, that the overhead of training the reversibility prediction may actually lead to keeping sup-optimal, irreversible behaviors for longer.
Non-Deterministic Actions
Finally, this was a rewarding one. For me, anyway. Not so much for the PPO agent, but we'll get to that. So, the environment here is FrozenLake [3]. The agent (small person with the green hat) starts at the small stool (top left), and has to reach the present (bottom right) to receive a reward of 1. Should the agent step into one of the holes, the environment ends and a reward of 0 is returned. Now to make this a stochastic environment: Every time the agent choses to move towards any direction, there is a 1/3 chance arrives as intended, and a 1/3 chance it ends up moving left or right respectively.

First I ran a pure PPO agent on the FrozenLake, using the same parameters as during the Turf world RAE training. I then plotted plotted the visiting rate, same as during the Turf experiment:

Remember when I said not very rewarding for PPO? Well, pure PPO to be exact. As mentioned, there is no reward at all unless the goal is reached. During random exploration, the chances of reaching the goal are extremely low, making the rewards very sparse. Subsequently, the agent cannot figure out how to reach the goal. In comparison, here is the performance of the agent trained using PPO+RAE:

The agent not only frequently reaches the goal, it also clearly avoids all holes, except the upper right one. So why does this work so well? In essence, by providing feedback regarding the irreversibility of stepping into a hole, the rewards become non-sparse. This allows the agent to learn to avoid the holes, thereby increasing the chances of eventually reaching the goal. Using the suddenly much higher reward, the agent quickly adjusts to always follow its already pretty optimal policy. Here is the reward over time to prove I did not make that up:
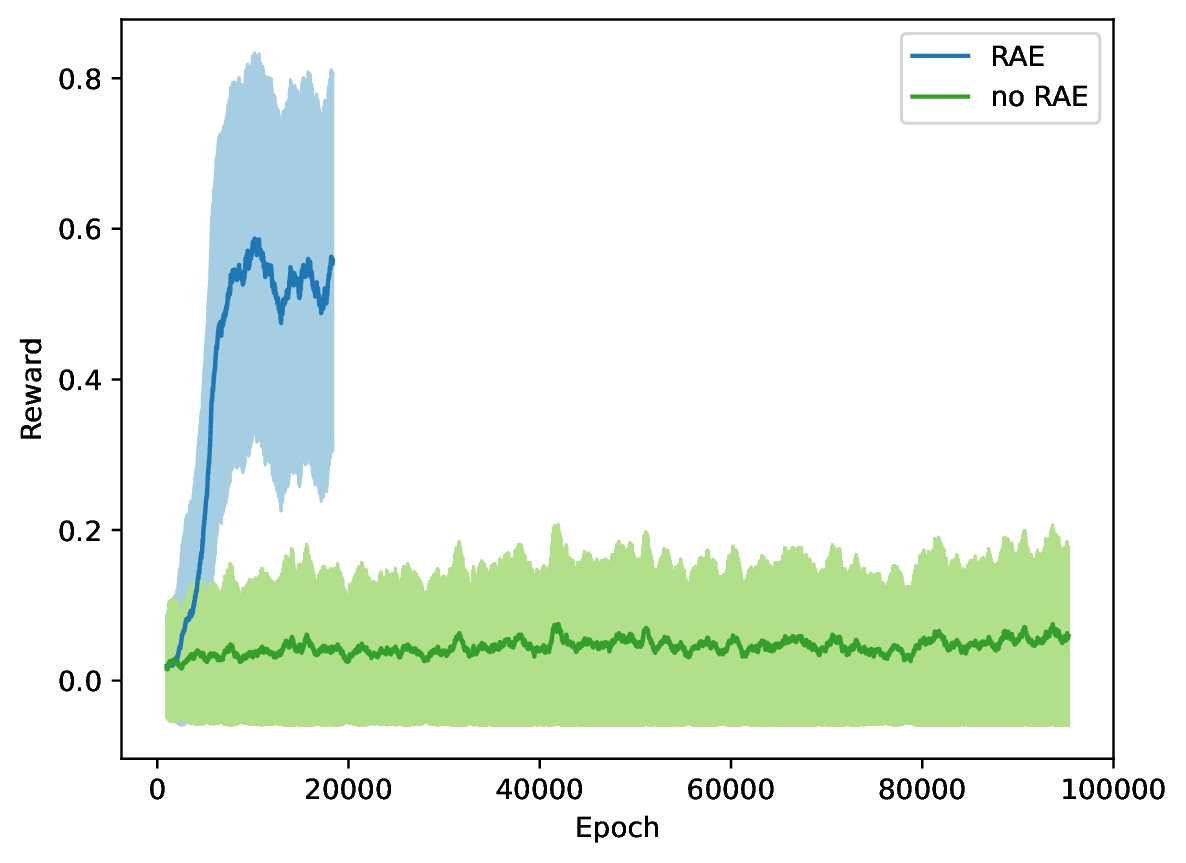
Note that both agents trained for the same amount of steps, with the PPO+RAE agent staying within the environment much longer. Like, much longer. What's going on there? This comes down to what an optimal policy in this environment looks like. Since walking into the edge means the agent stays in place, it can actually ensure it ends up where it wants to go by repeating one direction over and over until it succeeds. For example, until the agent reaches the field above the left-most hole, it should only walk to the left until eventually moving down twice, or moving down, up, down,... , up, down, down. You get the point. And this is something the agent was clearly only able to find out using the input of the RAE network. Short side-note before we move on to the conclusion: Of course the goal is also irreversible and is therefore punished by RAE. It is therefore detrimental, that the final reward is much bigger than the irreversibility penalty to ensure that the agent doesn't just turn around and keep moving. Obviously, this is only an issue in a finite environment like the ones presented and not necessarily in a real-world application.
Conclusion
You made it! Thanks for reading. I'll try to keep the conclusion short, I promise. Here are some of the Pro's:
Smart solution to a complex problem
Unique and very simple but flexible approach
Easy to implement and adjust
And the Con's:
Very hyperparameter-dependent
Struggles with larger state-spaces
Can be misused
I elaborated the Con's within my tests so I'll skip that here. Regarding the Pro's, take a look at their GitHub. There is more overhead, but the actual reversibility part consists of 3 files with ~450 lines of code. That's ridiculously little, while it still works great and can easily be adjusted for other environments. And looking at the original idea, this tiny implementation makes a lot of sense, as the idea itself is already extremely simple, which, to me, is its greatest strength. A lot of research dealing with any sort of intelligence or learning tend to take the "larger = better" approach, so seeing research done on a simple/small solution approach for a complex problem is very refreshing.

That being said, the authors still do not manage to fully rid themselves of this issue, as all predictions within this paper are learned via neural networks. These are of course extremely tiny (two layers each), but are therefore also limited to the extremely simple environments all mentioned tests were performed on. By implementing their simple idea like this, the only way forward becomes scaling up the neural networks, thereby quickly losing all trace of its original simplicity as well as its clever approach in another arms-race for the biggest functional function-approximator. Granted, temporal order may be impossible to learn any other way, but that just raises another question: Do we learn temporal order or do we actually learn something about reversibility?
I could imagine human perception being able to create a representation of a present state reduced to only the problem-relevant aspects, do the same for a potential future state, and have both representations just complex enough to be able to derive reversibility not via prediction, but simply via the difference between both representations. Reality will be a lot more complex of course, but if all approaches come down to "solved via function approximator", I highly doubt any of these algorithms will ever see similar results in a real world environment. I am not super optimistic, but I do hope more papers will eventually pick up this "simple = better" approach, and create much more robust algorithms capable of tackling tasks not as a computer, but as a human or other animal might. And who knows, maybe reversibility will be a key aspect?
References
[1] Nathan Grinsztajn and Johan Ferret and Olivier Pietquin and Philippe Preux and Matthieu Geist, “There Is No Turning Back: A Self-Supervised Approach for Reversibility-Aware Reinforcement Learning”, NeurIPS 2021.
[2] Nathan Grinsztajn. NoTurningBack [Website]. 2021. Available at: https://github.com/ https://github.com/nathangrinsztajn/NoTurningBack
[3] OpenAI. Frozen Lake[Website]. 2022. Available at: https://www.gymlibrary.dev/environments/toy_text/frozen_lake/